
پژوهشگران دانشگاه “ام.آی.تی” با همکاری دکتر “داریوش مهتا” دانشمند ایرانی، نوعی مدل مبتنی بر یادگیری ماشینی ارائه دادهاند که میتوانند به تصمیمگیری خودکار در حوزه پزشکی کمک کند.
به گزارش آردی نیوز و به نقل از ام.آی.تی نیوز، دانشمندان علوم رایانه دانشگاه “ام.آی.تی”(MIT) با همکاری دکتر “داریوش مهتا”(Daryush Mehta)، از اعضای مرکز جراحی حنجره “بیمارستان عمومی ماساچوست”(MGH) امیدوارند که بتوانند امکان استفاده از هوش مصنوعی را برای بهبود تصمیمگیری در حوزه پزشکی ارتقا دهند. آنها قصد دارند کاری که معمولا به صورت دستی انجام میشود و به خاطر گسترش مجموعه دادهها دشوار است، به صورت خودکار انجام دهند.
حوزه “تحلیل پیشگویانه”(Predictive analytics)، برای کمک به تشخیصهای بالینی و درمان بیماران بسیار امیدوارکننده هستند. مدلهای یادگیری ماشینی، این قابلیت را دارند که برای یافتن الگوهای مربوط به دادههای هر بیمار آموزش داده شوند و به تشخیص گندخونی و شیمیدرمانی ایمن کمک کنند و برای پیشبینی خطر ابتلا به بیماریهای وخیمی مانند سرطان پستان به کار روند.
مجموعه دادهها، معمولا اطلاعات افراد سالم و بیمار را در بر دارد اما دادههای کمی در مورد هر فرد را شامل میشود. متخصصان باید ویژگیهایی را در این مجموعه دادهها پیدا کنند که برای پیشبینی بیماریها مهم هستند.
“مهندسی ویژگی”(feature engineering)، فرآیندی دشوار و پرهزینه است اما در صورت افزایش استفاده از حسگرهای پوشیدنی، میتواند چالشهای بیشتری را به همراه داشته باشد. پژوهشگران با کمک حسگرهای پوشیدنی میتوانند اطلاعات مربوط به الگوهای خواب، راه رفتن و صدای بیمار را به سادگی بررسی کنند. پژوهشگران ام.آی.تی در بررسی جدید خود توانستند تنها پس از یک هفته بررسی اطلاعات بیماران، چند میلیارد نمونه داده برای هر بیمار ارائه دهند.
این پژوهش، مدلی را نشان میدهد که میتواند پیشبینی ویژگیهای مربوط به اختلالات صوتی را به صورت خودکار انجام دهد.
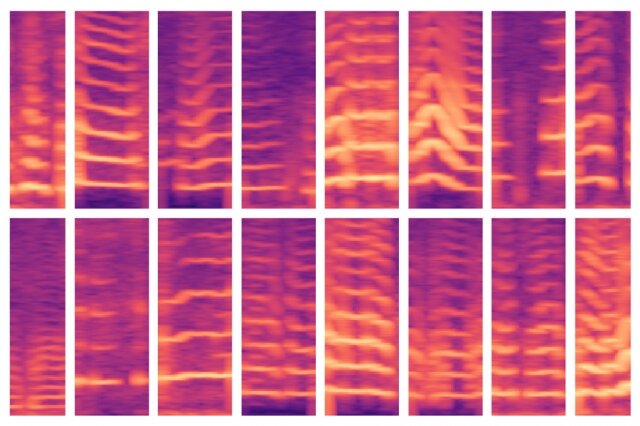
این ویژگیها، در یک مجموعه داده شامل حدود 100 بیمار جای گرفتهاند که دادههای مربوط به اختلالات صوتی هر یک از آنها را به همراه چند میلیارد نمونه در بر دارد. به عبارت دیگر، این مجموعه، تعداد کمی از افراد را با تعداد گستردهای از دادههای مربوط به هر یک در بر دارد. این مجموعه داده، سیگنالهایی را شامل میشود که از یک حسگر نصب شده روی گردن افراد به دست آمدهاند.
این مدل در آزمایشها، به صورت خودکار از ویژگیهای مربوط به دادهها استفاده میکند تا بیماران را با دقت بالا طبقهبندی کند. آسیبهایی که به حنجره وارد میشوند، معمولا در اثر استفاده بد از صدا مانند فریاد زدن پیش میآیند. مدل پژوهشگران ام.آی.تی میتواند این کار را بدون بررسی دستی مجموعه دادهها انجام دهد.
“ژوزه خاویر گونزالز اورتیز”(Jose Javier Gonzalez Ortiz)، دانشجوی مقطع دکتری دانشگاه ام.آی.تی و نویسنده ارشد این پژوهش گفت: شاید جمعآوری مجموعه دادهها در بلند مدت ساده باشد اما این کار به پزشکانی نیاز دارد که دانش خود را برای طبقهبندی مجموعه دادهها به کار ببرند. هدف ما این است تا بخشی که متخصصان باید به صورت دستی انجام دهند، حذف کنیم و مدل یادگیری ماشینی را به جای مهندسی ویژگی به کار ببریم.
مدل یادگیری ماشینی، این قابلیت را دارد تا برای یادگیری الگوهای هر بیماری مورد استفاده قرار گیرد. پژوهشگران باور دارند که توانایی شناسایی الگوهای روزانه صدا، گام مهمی در ابداع روشهای بهتر برای پیشگیری، تشخیص و درمان اختلالات صوتی به شمار میرود. این مدل میتواند به طراحی روشهای جدیدی برای شناسایی اختلالات صوتی و آگاه کردن افراد در مورد رفتارهای مضر برای صدا کمک کند.
این پژوهش، در نشست “یادگیری ماشینی برای مراقبت سلامتی” (MLHC) ارائه خواهد شد.